
Što je robots.txt i zašto je važan za SEO?
.jpg?preset=autorSlika)
 07.05.2024.
07.05.2024.
 10 minute čitanja
10 minute čitanja
Što je robots.txt datoteka?
Datoteka robots.txt skup je uputa koje web stranice koriste kako bi pretraživačima dali do znanja koje stranice treba i koje ne treba indeksirati, što znači da te datoteke usmjeravaju crawlere, ali se ne bi trebale koristiti za skrivanje stranica iz Googleovog indeksa.
Datoteke robots.txt mogu se činiti kompliciranima, ali njihova sintaksa (računalni jezik) je jednostavna.
Datoteke robots.txt mogu se činiti kompliciranima, ali njihova sintaksa (računalni jezik) je jednostavna.
Datoteka robots.txt izgleda ovako:

Zašto je robots.txt važan?
Datoteka robots.txt pomaže upravljati aktivnostima web crawlera tako da ne preopterete web stranicu ili indeksiraju stranice koje nisu namijenjene javnom prikazu.
Evo nekoliko razloga za korištenje datoteke robots.txt:
-
Optimizacija proračuna za indeksiranje
Proračun za indeksiranje odnosi se na broj stranica koje će Google indeksirati na vašem webu u određenom vremenskom razdoblju. Broj može varirati ovisno o veličini vaše stranice, njezinom zdravlju i broju backlinkova. Ako broj stranica vašeg weba premašuje proračun za indeksiranje, mogli biste imati neindeksirane stranice na vašoj stranici. Neindeksirane stranice neće se rangirati, i na kraju, gubite vrijeme stvarajući stranice koje korisnici neće vidjeti. Blokiranjem nepotrebnih stranica pomoću robots.txt dopuštate Googlebotu (Googleovom web crawleru) da više vremena provede indeksirajući stranice koje su važne.
Napomena: Većina vlasnika web stranica ne treba previše brinuti o proračunu za indeksiranje na Googleu. To je prvenstveno zabrinutost za veće stranice s tisućama URL-ova.
-
Blokiranje duplikata i stranica koje nisu za javnost
Crawleri ne moraju prolaziti kroz svaku stranicu na vašem webu, jer nisu sve stvorene za prikazivanje na stranicama rezultata pretraživača (SERP-ovima), kao što su staging stranice, stranice internih rezultata pretraživanja, duplicirane stranice ili stranice za prijavu. Neki sustavi upravljanja sadržajem sami rješavaju te interne stranice. WordPress, na primjer, automatski zabranjuje pristup stranici za prijavu /wp-admin/ svim crawlerima, a robots.txt vam omogućava da ručno blokirate pristup bilo kojoj stranici vašeg weba za crawlere.
-
Skrivanje resursa
Kako funkcionira datoteka robots.txt?
Datoteke robots.txt govore botovima pretraživača koje URL-ove mogu indeksirati, a što je još važnije, koje URL-ove trebaju ignorirati.
Pretraživači imaju dvije glavne svrhe:
- Pregledavanje weba kako bi otkrili sadržaj
- Indeksiranje i dostavljanje sadržaja pretraživačima koji traže informacije
Dok pretražuju web stranice, botovi pretraživača otkrivaju i prate poveznice. Taj proces ih vodi s mjesta A na mjesto B na mjesto C kroz milijune poveznica, stranica i web stranica. No, ako bot naiđe na datoteku robots.txt, prvo će je pročitati prije nego što išta učini. Sintaksa je jednostavna. Pravila se određuju identifikacijom user-agenta (bot pretraživača), nakon čega slijede upute (pravila). Također možete koristiti znak zvjezdice (*) kao zamjenski znak za dodjelu uputa svakom korisničkom agentu, što primjenjuje pravilo na sve botove.
Na primjer, sljedeća uputa dopušta svim botovima osim DuckDuckGo da indeksiraju vašu stranicu:
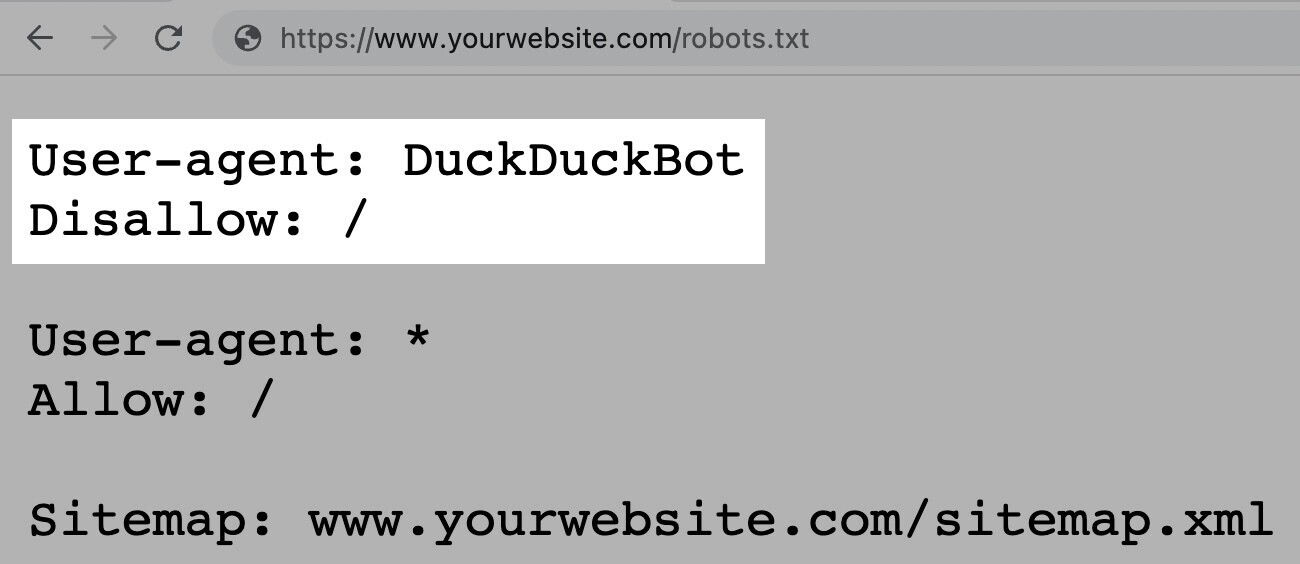
Napomena: Iako datoteka robots.txt daje upute, one se ne mogu prisilno provesti. Možete to shvatiti kao kodeks ponašanja. Dobri botovi (poput botova pretraživača) će slijediti pravila, ali loši botovi (poput spam botova) će ih ignorirati.
Kako pronaći datoteku robots.txt?
Datoteka robots.txt nalazi se na vašem serveru, baš kao i bilo koja druga datoteka na vašoj web stranici. Pogledajte datoteku za bilo koju web stranicu tako što ćete upisati puni URL početne stranice i na kraju dodati "/robots.txt", kao u ovom primjeru: https://www.tiktok.com/robots.txt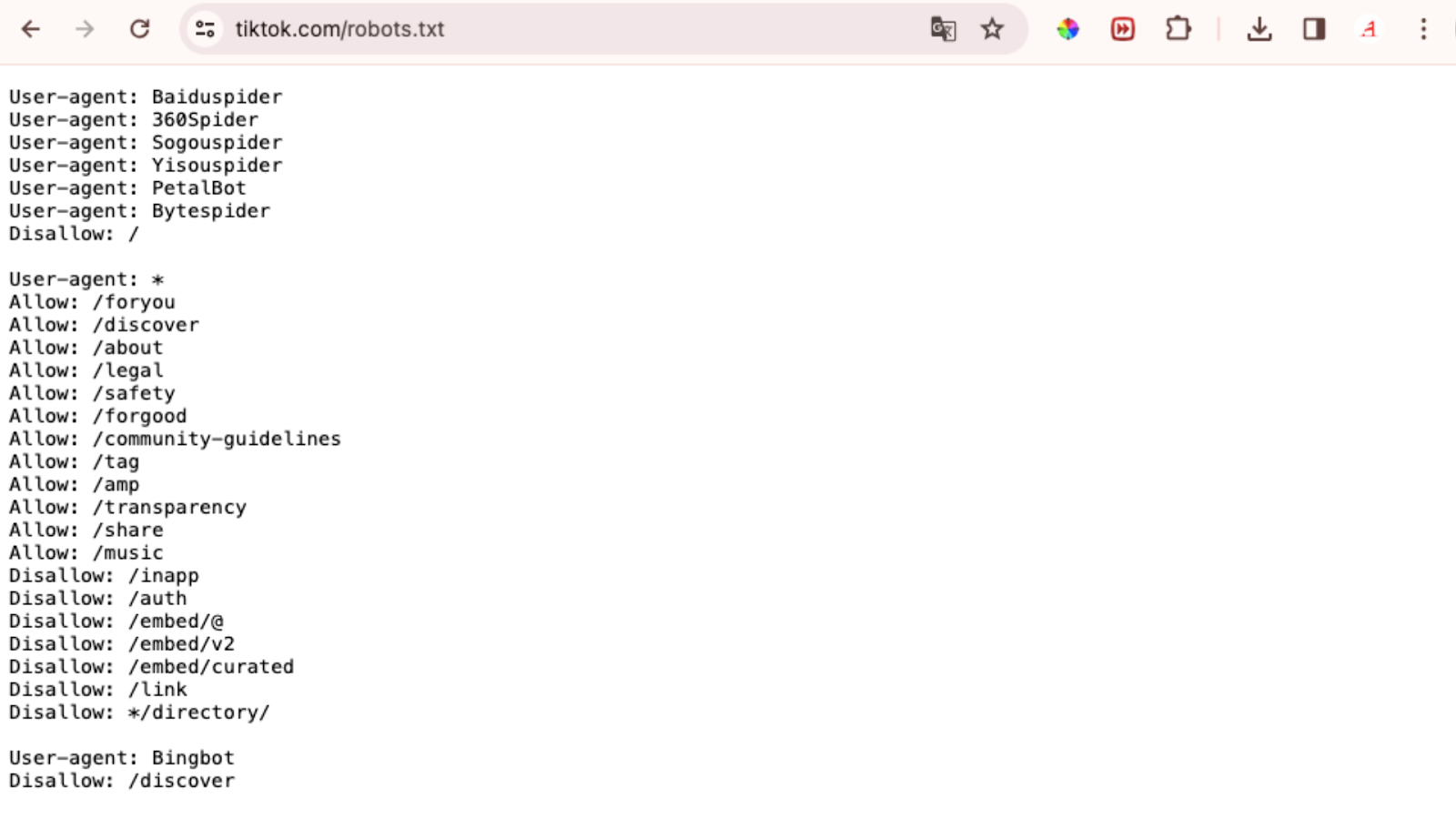
Napomena: Datoteka robots.txt uvijek bi trebala biti smještena na razini root domene. Za www.tiktok.com, datoteka robots.txt nalazi se na www.tiktok.com/robots.txt. Ako je smjestite negdje drugdje, crawleri mogu pretpostaviti da je nemate.
Prije nego što naučimo kako stvoriti datoteku robots.txt, pogledajmo njenu sintaksu koja se sastoji od:
- Jednog ili više blokova "uputa" (pravila)
- Svaki s određenim "user-agent" (search engine bot)
- I uputom "allow" ili "disallow"
Prvi redak svakog bloka uputa je korisnički agent, koji identificira crawlera.
Napomena: Većina pretraživača ima više crawlera. Koriste različite crawlere za standardno indeksiranje, slike, videozapise itd. Kada je prisutno više uputa, bot može odabrati najspecifičniji blok uputa koji je dostupan. Recimo da imate tri seta uputa: jedan za *, jedan za Googlebot i jedan za Googlebot-Image. Ako korisnički agent Googlebot-News pretražuje vašu stranicu, slijedit će upute za Googlebot. S druge strane, korisnički agent Googlebot-Image slijedit će specifičnije upute za Googlebot-Image.
Drugi redak direktive robots.txt je linija "Disallow".
Možete imati više direktiva "Disallow" koje određuju koje dijelove vaše stranice crawler ne može pristupiti. Prazna linija "Disallow" znači da ne zabranjujete ništa—crawler može pristupiti svim dijelovima vaše stranice.
Napomena: Direktive poput "Allow" i "Disallow" nisu osjetljive na veličinu slova. Ali vrijednosti unutar svake direktive jesu. Na primjer, /photo/ nije isto što i /Photo/. Ipak, često ćete naći da su direktive "Allow" i "Disallow" napisane velikim slovima kako bi datoteka bila lakša za čitanje ljudima.
Direktiva "Allow"
Direktiva "Allow" omogućava pretraživačima da indeksiraju poddirektorij ili određenu stranicu, čak i unutar direktorija koji je inače zabranjen.
Napomena: Ne prepoznaju sve tražilice ovu naredbu. No, Google i Bing podržavaju ovu direktivu.
Napomena: Ne prepoznaju sve tražilice ovu naredbu. No, Google i Bing podržavaju ovu direktivu.
Direktiva Sitemap
Direktiva Sitemap govori pretraživačima, posebno Bingu, Yandex i Googleu, gdje mogu pronaći vaš XML sitemap. Sitemape obično uključuju stranice koje želite da pretraživači indeksiraju i ona se nalazi na vrhu ili na dnu datoteke robots.txt i izgleda ovako:
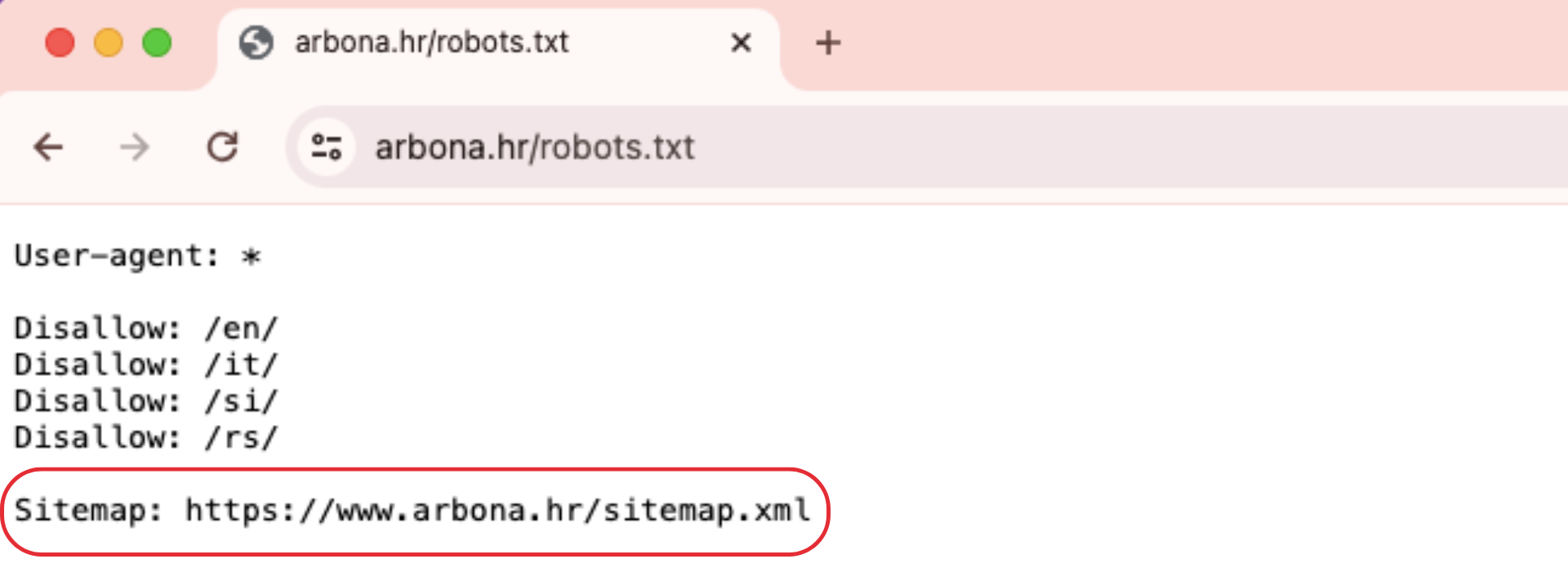
Dodavanje direktive Sitemap u vašu datoteku robots.txt brza je alternativa. No, trebali biste (i morate) također predati svoj XML sitemap svakoj tražilici koristeći njihove alate za webmastere. Tražilice će na kraju indeksirati vašu stranicu, ali predaja sitemap-a ubrzava proces indeksiranja.
Direktiva Crawl-Delay
Direktiva Crawl-Delay nalaže crawlerima da odgode svoje stope indeksiranja kako bi se izbjeglo preopterećenje servera (npr., usporavanje vaše web stranice). Google više ne podržava direktivu Crawl-Delay. Ako želite postaviti svoju stopu indeksiranja za Googlebot, morat ćete to učiniti u Search Consoli. Bing i Yandex, s druge strane, podržavaju direktivu Crawl-Delay.
Direktiva Noindex
Datoteka robots.txt govori botu što može ili ne može indeksirati, ali ne može reći pretraživaču koje URL-ove ne indeksirati i ne prikazivati u rezultatima pretraživanja. Google nikada službeno nije podržao ovu direktivu, ali 1. rujna 2019. godine Google je objavio da ova direktiva nije podržana.
Ako želite pouzdano isključiti stranicu ili datoteku iz pojavljivanja u rezultatima pretraživanja, izbjegavajte u potpunosti ovu direktivu i koristite meta robots noindex oznaku.
Ako želite pouzdano isključiti stranicu ili datoteku iz pojavljivanja u rezultatima pretraživanja, izbjegavajte u potpunosti ovu direktivu i koristite meta robots noindex oznaku.
Kako stvoriti datoteku robots.txt
Možete koristiti alat za generiranje datoteke robots.txt ili je stvoriti sami.
Stvorite datoteku i imenujte je Robots.txt. Započnite otvaranjem .txt dokumenta unutar tekstualnog uređivača ili web preglednika. Nemojte koristiti uređivač teksta koji pohranjuje datoteke u vlastitom formatu jer mogu dodati slučajne znakove. Zatim, imenujte dokument robots.txt. Sada ste spremni početi unositi direktive.
Dodajte direktive u datoteku Robots.txt. Datoteka robots.txt sastoji se od jedne ili više grupa direktiva, a svaka grupa sastoji se od više redaka uputa. Svaka grupa započinje s "user-agent" i sadrži sljedeće informacije:
Stvorite datoteku i imenujte je Robots.txt. Započnite otvaranjem .txt dokumenta unutar tekstualnog uređivača ili web preglednika. Nemojte koristiti uređivač teksta koji pohranjuje datoteke u vlastitom formatu jer mogu dodati slučajne znakove. Zatim, imenujte dokument robots.txt. Sada ste spremni početi unositi direktive.
Dodajte direktive u datoteku Robots.txt. Datoteka robots.txt sastoji se od jedne ili više grupa direktiva, a svaka grupa sastoji se od više redaka uputa. Svaka grupa započinje s "user-agent" i sadrži sljedeće informacije:
- Na koga se grupa odnosi (user-agent)
- Koje direktorije (stranice) ili datoteke agent može pristupiti
- Koje direktorije (stranice) ili datoteke agent ne može pristupiti
- Sitemap (opcionalno) kako biste pretraživačima rekli koje stranice i datoteke smatrate važnima
Crawleri ignoriraju redove koji ne odgovaraju ovim direktivama. Na primjer, recimo da ne želite da Google indeksira vaš direktorij /clients/ jer je to samo za internu upotrebu.
Prva grupa bi izgledala ovako:

Dodatne upute mogu se dodati u zasebnom redu ispod, ovako:

Kada završite s Googleovim specifičnim uputama, pritisnite enter dvaput da biste stvorili novu grupu direktiva. Napravimo ovu za sve pretraživače i spriječimo ih da indeksiraju vaše direktorije /archive/ i /support/ jer su samo za internu upotrebu.
Izgledalo bi ovako:

Kada završite, dodajte svoj sitemap.
Vaša završna datoteka robots.txt izgledala bi ovako:

Spremite svoju datoteku robots.txt.
Napomena: Crawleri čitaju odozgo prema dolje i usklađuju se s prvim najspecifičnijim grupama pravila. Dakle, započnite svoju datoteku robots.txt s posebnim korisničkim agentima, a zatim pređite na općenitiji zamjenski znak (*) koji odgovara svim crawlerima.
Ukoliko želite ostaviti koji komentar, pravilno je koristiti # na početku retka. Obzirom da se te stranice rijetko otvaraju, programeri se znaju malo zaigrati. Tako smo i našili na Nike logo unutar njihove datoteke - https://www.nike.com/robots.txt.
Napomena: Crawleri čitaju odozgo prema dolje i usklađuju se s prvim najspecifičnijim grupama pravila. Dakle, započnite svoju datoteku robots.txt s posebnim korisničkim agentima, a zatim pređite na općenitiji zamjenski znak (*) koji odgovara svim crawlerima.
Ukoliko želite ostaviti koji komentar, pravilno je koristiti # na početku retka. Obzirom da se te stranice rijetko otvaraju, programeri se znaju malo zaigrati. Tako smo i našili na Nike logo unutar njihove datoteke - https://www.nike.com/robots.txt.

Nakon što ste spremili datoteku robots.txt na svoje računalo, prenesite je na svoju stranicu i učinite je dostupnom za indeksiranje pretraživačima. Prijenos datoteke robots.txt ovisi o strukturi datoteka vaše stranice i web hostingu. Nakon prijenosa, provjerite može li je svatko vidjeti i može li je Google čitati.
Sljedeći korak je testiranje. Prvo, testirajte je li vaša datoteka robots.txt javno dostupna (tj. je li ispravno prenesena), Otvorite privatni prozor u svom pregledniku i pretražite svoju datoteku robots.txt. Ako vidite svoju datoteku s dodanim sadržajem, spremni ste testirati oznaku (HTML kod).
Sljedeći korak je testiranje. Prvo, testirajte je li vaša datoteka robots.txt javno dostupna (tj. je li ispravno prenesena), Otvorite privatni prozor u svom pregledniku i pretražite svoju datoteku robots.txt. Ako vidite svoju datoteku s dodanim sadržajem, spremni ste testirati oznaku (HTML kod).
Google nudi dvije opcije za testiranje oznake robots.txt:
- Tester robots.txt u Search Console
- Googleova open-source knjižnica robots.txt (napredno)
Budući da je druga opcija namijenjena naprednim programerima, testirajmo vašu datoteku robots.txt u Search Console.
Napomena: Morate imati postavljen račun na Google Search Console.
Idite na Tester robots.txt i kliknite na "Open robots.txt Tester" i otvorite ga. Ako niste povezali svoju web stranicu s vašim računom Google Search Console, prvo ćete morati dodati svojstvo. Zatim, potvrdite da ste stvarni vlasnik stranice.
Ako imate postojeća verificirana svojstva, odaberite jedno iz padajućeg izbornika na početnoj stranici. Tester će identificirati upozorenja na sintaksu ili logičke greške i prikazat će ukupan broj upozorenja i grešaka ispod urednika. Možete izravno na stranici uređivati greške ili upozorenja i ponovno testirati dok radite.
Sve promjene neće biti spremljene na vašoj stranici, niti alat mijenja stvarnu datoteku na vašoj stranici, već testira kopiju u alatu. Da biste implementirali bilo kakve promjene, kopirajte i zalijepite uređenu testnu kopiju u datoteku robots.txt na vašoj stranici.
Napomena: Morate imati postavljen račun na Google Search Console.
Idite na Tester robots.txt i kliknite na "Open robots.txt Tester" i otvorite ga. Ako niste povezali svoju web stranicu s vašim računom Google Search Console, prvo ćete morati dodati svojstvo. Zatim, potvrdite da ste stvarni vlasnik stranice.
Ako imate postojeća verificirana svojstva, odaberite jedno iz padajućeg izbornika na početnoj stranici. Tester će identificirati upozorenja na sintaksu ili logičke greške i prikazat će ukupan broj upozorenja i grešaka ispod urednika. Možete izravno na stranici uređivati greške ili upozorenja i ponovno testirati dok radite.
Sve promjene neće biti spremljene na vašoj stranici, niti alat mijenja stvarnu datoteku na vašoj stranici, već testira kopiju u alatu. Da biste implementirali bilo kakve promjene, kopirajte i zalijepite uređenu testnu kopiju u datoteku robots.txt na vašoj stranici.
Datoteka robots.txt nezaobilazan je alat za svakog vlasnika web stranice koji želi upravljati kako pretraživači indeksiraju njihov sadržaj. Korištenjem jednostavne sintakse, ova datoteka omogućava webmasterima da dirigiraju botove pretraživača, upućujući ih koje dijelove stranice mogu pregledavati, a koje bi trebali izbjegavati. Iako se robots.txt primarno koristi za sprječavanje preopterećenja servera i optimizaciju proračuna za indeksiranje, važno je zapamtiti da ona ne osigurava potpunu privatnost niti može u potpunosti spriječiti indeksiranje ako se to ne kombinira s drugim metodama poput meta tagova noindex.
Pametno korištenje datoteke robots.txt može značajno poboljšati SEO vaše stranice usmjeravanjem botova na važan sadržaj i odvraćanjem od nepotrebnih ili dupliciranih stranica. Za web stranice s velikim brojem poddomena, posebno je važno stvoriti zasebne robots.txt datoteke za svaku poddomenu, osiguravajući da botovi pravilno indeksiraju sadržaj na svakoj od njih. Na kraju, pravilno upravljanje i testiranje vaše datoteke robots.txt osigurat će da pretraživači pravilno tumače vaše upute, što će doprinijeti boljem rangiranju i vidljivosti vaše web stranice na internetu.
Pametno korištenje datoteke robots.txt može značajno poboljšati SEO vaše stranice usmjeravanjem botova na važan sadržaj i odvraćanjem od nepotrebnih ili dupliciranih stranica. Za web stranice s velikim brojem poddomena, posebno je važno stvoriti zasebne robots.txt datoteke za svaku poddomenu, osiguravajući da botovi pravilno indeksiraju sadržaj na svakoj od njih. Na kraju, pravilno upravljanje i testiranje vaše datoteke robots.txt osigurat će da pretraživači pravilno tumače vaše upute, što će doprinijeti boljem rangiranju i vidljivosti vaše web stranice na internetu.


